

 数达安全数据静态脱敏系统V3R3版本白皮书
数达安全数据静态脱敏系统V3R3版本白皮书
数达安全数据静态脱敏系统(简称DS-DM),是高性能、高安全性的脱敏产品。集成了丰富的敏感数据扫描规则和专业的脱敏规则,满足各个行业对于隐私数据的脱敏需求。V3系列产品是敏感(隐私)数据脱敏产品的升级版本,增加了实用且重要的功能,扩展了脱敏产品的使用场景和范围。

产品功能
数据源
能够对源和目标进行配置与管理, 采用多种数据抽取方式,面向所有的数据库应用环境提供通用的数据处理模式,针对部分数据库应用环境提供了极速的数据处理模式。
数据浏览
主要是对源和目标进行数据浏览操作,支持查看基本信息、表信息、列信息以及数据对象等。
敏感数据定级
率先推出了敏感数据定级功能,提供了高敏感度、中敏感度、低敏感度三个等级,对敏感数据进行分类和分级。
分级分类梳理
V3系列产品引入了以敏感数据定级为依据的分类分级梳理方式,让敏感数据定级和数据梳理相辅相成,提供可以落地的隐私数据脱敏标准和依据。
数据子集
V3系列产品在对单个表进行数据脱敏的基础上,通过表与表之间的主外键关联关系,可以对多个表的任意列进行组合脱敏。并根据已设定的数据(跨表的多列组合)范围,可自动完成子集数据抽取、脱敏,然后将数据写入到一张新表中。
增量脱敏
为了满足持续增长的业务数据脱敏需求,增量脱敏可以帮助用户保持测试库中脱敏后的数据总量和生产库中的原始数据总量相同,通过自增主键或者时间戳列等方式获取新增数据的位置以及行数,由定时的脱敏任务对这部分新增的数据进行脱敏,然后通过追加数据的方式写入测试环境。
数据水印
能够对所有已脱敏的数据增加数据水印标记,通过脱敏任务装载至目标数据库或者文件服务器上。
数据脱敏
用户可以根据实际的业务需要选择:数据遮蔽、数据仿真、关键部分替换、随机字符串、重置固定值等多种多样的脱敏方式,隐藏真实有效的敏感数据信息。所有的数据均在内存中进行处理,提高数据使用的安全性。脱敏后的数据仍然保留原有的语义、长度和关联关系。支持数据的可逆脱敏。
数据对比
提供脱敏前后数据校验功能。任务完成后,可以直接查看源和目标的结构、数据对象类型和数量、表的结构和数量、表内的数据量等。通过多个角度进行分析对比,帮助用户检查脱敏任务运行的完整性,以及脱敏后的数据质量是否满足预期要求。
敏感管理
主要对内置的扫描规则、脱敏规则和正则表达式进行配置和管理。还提供数据字典管理、自定义函数和混合函数等自定义规则,方便用户根据实际需求进行配置。
数据同步
能够自动获取数据库的结构变更,保持测试环境的表数量和生产环境一致。
脱敏审批流程
提供了基于脱敏流程的审批机制,将脱敏流程划分为多个角色。通过多个角色的相互配合,能够帮助用户完成跨越多个部门的数据使用申请、脱敏方案审核、脱敏任务审核、数据分发等操作。
多租户模式
提供了基于数据源的隔离(多租户)模式,将数据源和用户进行绑定,绑定后的用户才能对数据源进行脱敏业务操作。
产品优势
丰富的敏感数据识别能力
静态脱敏系统对电力、公安、社保、工商、税务、银行等多个行业的数据特征进行了详细分析的基础上针对性的提供了丰富的数据识别特征,包含有:电子邮箱、中文地址、公司名称、单位名称、中文姓名、手机号、座机号、日期、税号、统一社会信用代码、身份证、金额、银行卡号、港澳通行证等几十种敏感数据特征。
还提供了正则表达式、自定义函数等多种方式的规则接口,以及基于多种敏感数据的混合类型规则配置和独有的数据特征字典配置。用户可以根据实际的业务需要,灵活的制定符合自身数据特点的扫描规则。减少因为通用的规则不满足行业数据特性带来的识别准确率下降问题,从而有效避免了敏感数据泄露。
专业的脱敏规则
由于行业不同,各行业的数据格式、语义也不尽相同。面对不同的数据类型、长度等情况,静态脱敏系统提供了适用于大多数字符型数据的:按位遮蔽、随机字符串、固定值和Hash(加盐)等四种通用的脱敏规则,结合数据方向、起始位置等参数设置,满足通用类型数据的脱敏要求。
在通用的脱敏规则基础上,针对每种敏感数据均提供了:仿真、遮蔽、可逆三种专有规则。使用可逆规则脱敏后的数据,再次经过脱敏设备处理后,可以将指定范围内的数据还原为原数据。
以上每种脱敏效果均提供默认的参数可以调整,当以上的所有的规则仍然不能满足要求时,通过开放的规则接口,用户可以灵活定制脱敏规则,提升产品在实际业务运用过程中的实用性和专业性。
详细的敏感数据定级统计报表
敏感数据定级,能够帮助用户将发现敏感数据类型进行分级分类,为制定有针对性的脱敏规则和规范提供依据。
通过敏感数据定级的统计报表,用户可以非常直观的查看整体的敏感数据等级分布情况,以及每个敏感等级包含的敏感数据类型和占比。
敏感数据定级还可以和数据库审计产品进行信息共享,对隐私数据进行全面的追踪和监控,及时发现隐私数据的访问异常行为。
完善的脱敏方式和规范
通过分级分类梳理视角自动为每个敏感等级提供了默认的脱敏规则和参数,使用分级分类梳理能够为用户带来以下效益:
隐私数据的脱敏方式有章可循,有标准可用;
使用敏感类型作为梳理视角,从容应对万张表以上的敏感数据梳理,快速完成全库全量数据的脱敏任务配置;
降低了用户在数据脱敏使用过程中对于专业人员的依赖。
灵活的数据范围选择机制
静态脱敏系统支持根据各类数据的应用场景如系统开发、测试、数据分析等,制定不同的脱敏方案,对需要脱敏的数据范围进行多角度的数据过滤选择,满足使用者对数据范围的精细化定义要求。
根据已设定的数据子集范围,能够自动完成子集数据抽取、脱敏,然后将数据写入到一张新表中,有效的减轻了用户在制定脱敏任务前,对数据使用方要求的数据范围划定、数据查询、转存的准备工作。
通过增量脱敏配置,结合周期运行的定时脱敏任务,能够保证增量的部分数据及时的被抽取,进行脱敏后,装载至目标。保证开发、测试或者大数据分析平台和生产环境保持数据实时同步。
静态脱敏系统对脱敏业务的全流程提供了标准的API接口,可以和各类应用、4A审批流程等系统,进行深度的融合,帮助用户减少任务配置的工作量,简化脱敏业务流程,同时更能够帮助用户严格控制脱敏后的数据分发和使用。
强大的兼容能力
静态脱敏系统面向所有行业用户,提供了强大的数据源、脱敏流程、脱敏场景的兼容能力,主要支持的库类型、文件类型和脱敏流程有:
支持市场上主流的数据库类型:Oracle、Mysql、MSSQL、Sybase、PostgreSQL等;
支持金融行业常用的数据库类型:DB2、Informix等;
支持医疗行业常用的数据库类型:Cache等;
支持多个国产化数据库类型:Gbase8A、Gbase8T、Gbase8S等;
支持NoSQL数据库: Redis、MongoDB、Maxcompute等;
支持内存数据库:IMPALA等;
支持主流的大数据平台:Hadoop Hive、Hbase、星环TDH等;
支持多种格式化数据文件:CSV、TXT、EXCEL、XML、JSON、DMP;
支持多种中文字符集: GBK、GB2312、UTF-8、Unicode;
支持多种文件读写方式:本地、FTP、SFTP、HDFS;
支持多种数据库的异构脱敏场景;
支持多种脱敏流程:库到库、库到文件、本地脱敏、文件到文件、文件到库。
高效的软硬件架构
高性能:支持单机或者集群部署方式,有效的提升多任务的并行数据处理能力;
可靠性高:基于服务器平台打造,LINUX系统,运行更稳定;
易操作:多种功能交互视角,操作更流畅,更简单、更高效;
易扩展:软件层面提供标准API接口,方便后期和其他平台对接。
典型部署
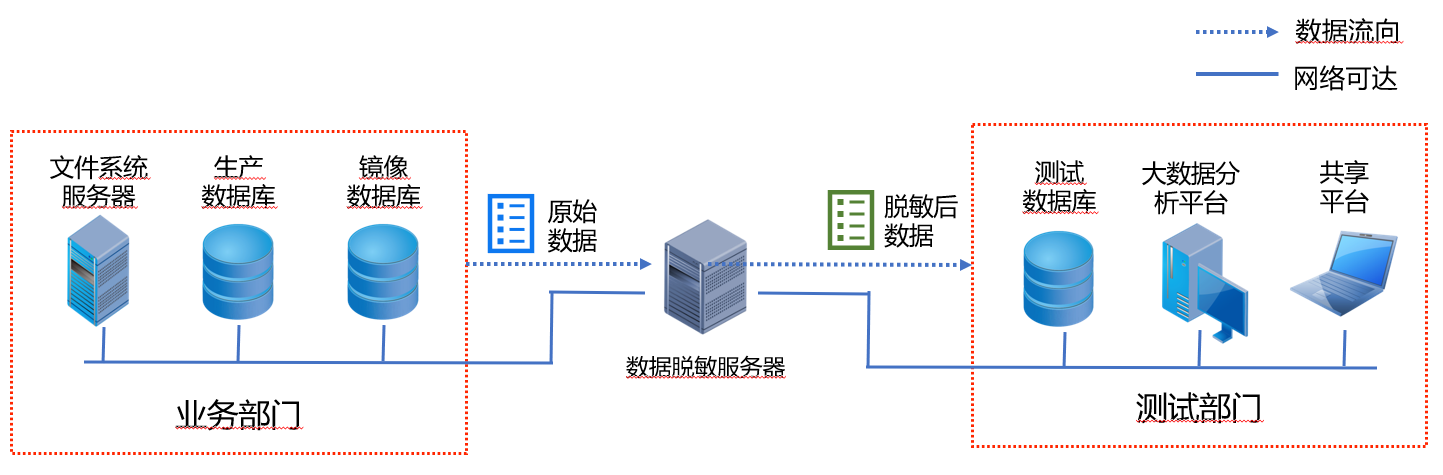
单机部署
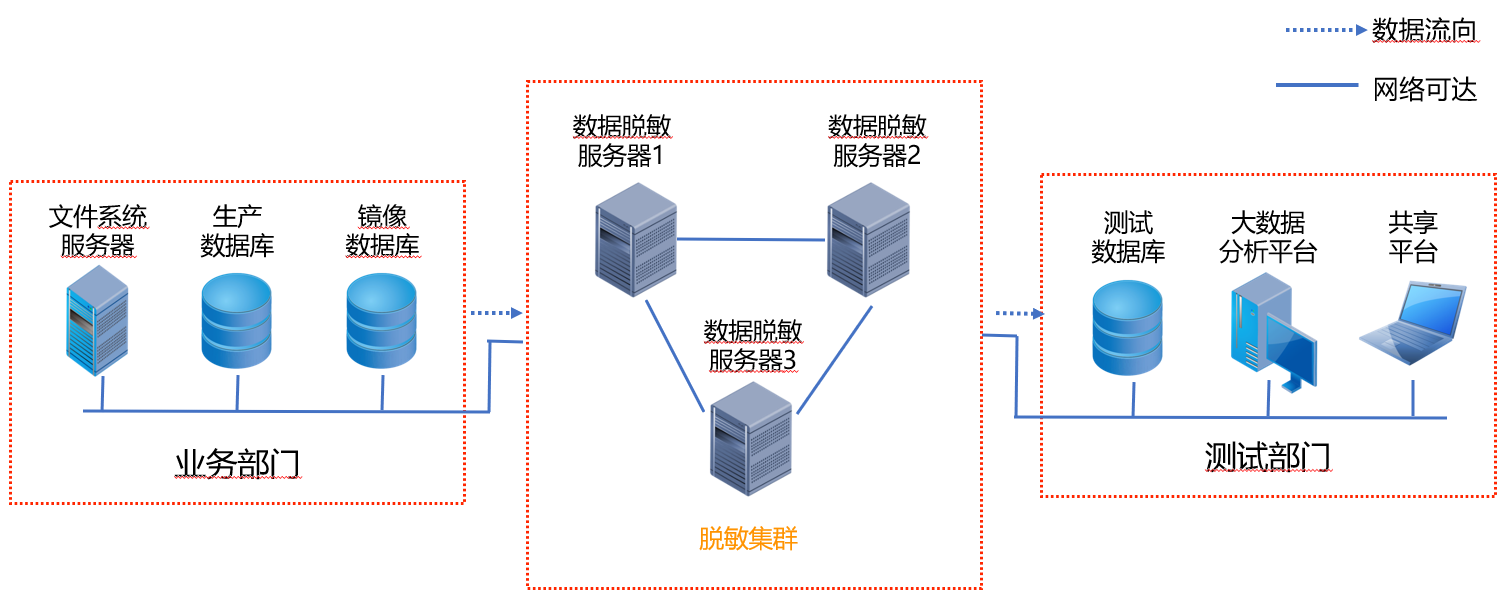
集群部署
产品价值
保护隐私数据,满足法规要求
通过对静态脱敏系统的使用,能够帮助用户杜绝生产环境中的核心数据在未经处理的情况下,被复制、分发到其他的开放环境中,有效的防止敏感数据泄露的事件发生。提高企业核心数据的治理和防护能力,提升整体的安全等级,满足合规性要求。
多方位保证业务的安全、正常运行
通过合理的规则设置,脱敏后数据的真实性完全满足大数据分析环境下的严苛要求。在避免敏感数据外泄的前提下,保证了各类需要使用生产数据的相关业务的正常推进。

